
Logseq 是一款双链笔记软件,也是 Roam Research 的模仿者中最有模有样的。在 Logseq 中,一旦将媒体文件粘贴到笔记中,其将被保存到 Logseq 目录下的 assets 文件夹中。但如果你从笔记中删掉了媒体文件,assets 文件夹中的图片并不会随着引用计数变成 0 而被自动删除。这就导致时间长了可能累计出一些“僵尸”媒体文件。
解决思路
要去除这些“僵尸”媒体文件,其实也非常简单。大体的思路就是:
- 扫描 assets 文件夹,获得所有 asset 文件名称
- 扫描 journals 和 pages 文件夹中的 .md 文件,检查其是否包含第一步中获得的 asset 文件名称
- 输出所有未被引用的 asset 文件列表
让 ChatGPT 写程序,可行吗?
这么简单的需求,是不是交给最近火热的 ChatGPT 来做比较好呢?于是我尝试向它提问:
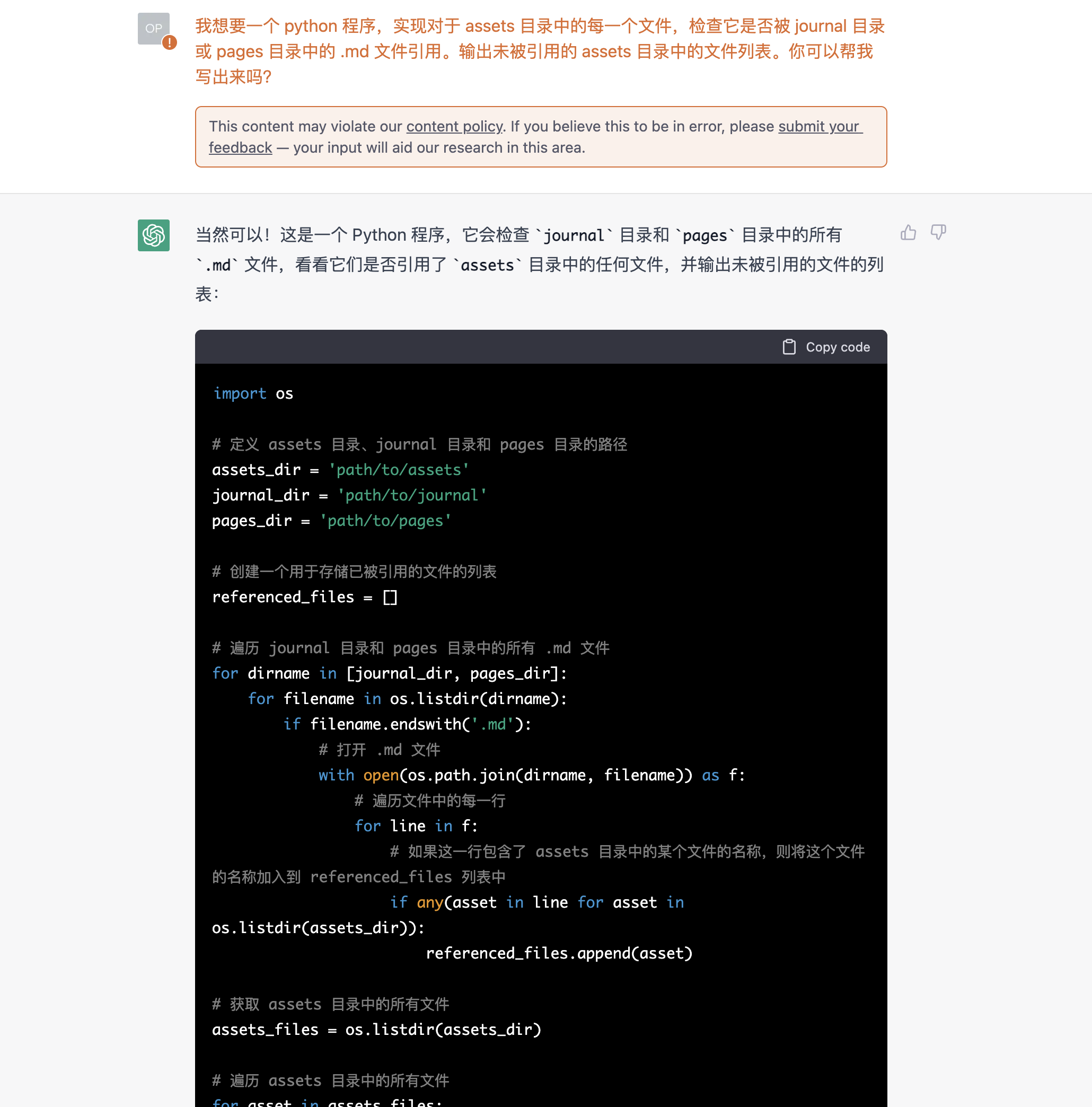
很可惜,虽然它的回答大体上逻辑都是对的,但是有一行却使用了无效的 Python 语法。这也说明一个问题,就是 ChatGPT 即便可以在训练时获取互联网上的所有知识,但他仍然是在这些知识中间做简单的拼贴,没有真正“理解”这些知识。
中文房间实验
上述 ChatGPT 的表现让我想到了美国哲学教授约翰·希尔勒提出的一个思想实验:中文房间实验。他的实验过程大概表述如下:
一个对中文一窍不通,只说英语的人关在一间只有一个开口的封闭房间中。房间里有一本用英文写成的手册,指示该如何处理收到的中文讯息及如何以中文相应地回复。房外的人不断向房间内递进用中文写成的问题。房内的人便按照手册的说明,查找合适的指示,将相应的中文字符组合成对问题的解答,并将答案递出房间。
尽管房里的人可以以假乱真,让房外的人以为他说中文,但事实上他根本不懂中文。在上述过程中,房外人的角色相当于 ChatGPT 的用户,房中人相当于计算机,而手册则相当于计算机程序:每当房外人给出一个输入,房内的人便依照手册给出一个答复(输出)。而正如房中人不可能透过手册理解中文一样,计算机也不可能透过程序来获得理解力。既然计算机没有理解能力,所谓“计算机于是便有智能”便更无从谈起了。
虽然现在很多自媒体都在用 ChatGPT 恰饭,通过抬高其能力以让自己获得流量,但我亲身体验过之后,感觉它仍然是一个很弱的语言模型,而非什么强人工智能。而官方也一再借 ChatGPT 之口表示自己的局限性,希望大家不要期待过高。看起来官方也是挺克制的,没有像自媒体一样硬恰。
改进 ChatGPT 输出的程序
我尝试向 ChatGPT 提出它写的代码有 bug,于是其给出了另一段程序以解决 bug。这段代码终于是正确的了,但是性能上仍然存在优化空间。例如,对于扫描文件夹这样的重 IO 操作,哪怕是水平比较一般的程序员也知道需要在代码中复用扫描结果,而不是重复进行扫描。但是 ChatGPT 写的程序却没有想到这一点。
于是,我改进了它写的程序,并获得了最终的代码:
import os
import shutil
assets_dir = './assets'
journal_dir = './journals'
pages_dir = './pages'
to_delete_dir = './to_delete'
if not os.path.exists(to_delete_dir):
os.makedirs(to_delete_dir)
assets_files = os.listdir(assets_dir)
referenced_files = []
for dirname in [journal_dir, pages_dir]:
for filename in os.listdir(dirname):
if filename.endswith('.md'):
# 打开 .md 文件
with open(os.path.join(dirname, filename)) as f:
# 遍历文件中的每一行
for line in f:
# 遍历 assets 目录中的所有文件
for asset in assets_files:
# 如果这一行包含了 assets 目录中的某个文件的名称,则将这个文件的名称加入到 referenced_files 列表中
if asset in line:
referenced_files.append(asset)
for asset in assets_files:
if asset not in referenced_files and not asset.endswith(".edn"):
print(asset)
shutil.move(os.path.join(assets_dir, asset), to_delete_dir)将这段代码放置在你的 Logseq 文件夹目录下,命名为 check_asset_reference.py。然后进入终端,来到 Logseq 目录下,输入 python check_asset_reference.py 并回车。稍等片刻后,你将会看到未被任何 journal 或 page 引用的 asset 列表:
这些文件会被移动到你的 Logseq 目录下的 `to_delete` 文件夹中。你需要手动确认这些文件是否真的可以删除,如果确认的话,手动进行删除。如果有文件不能删除的话,将它移回 assets 目录,并在任何一个 page 或 journal 中进行引用即可。
“玩物生智”是本博客的一个频道。我会在此分享一系列普通人在使用计算机等电子产品时会遇到的问题,以及对应的清晰易懂的解决方案。力求让技术为我们服务,提升个人使用电子产品的使用体验。如果你对此感兴趣,不妨在下方订阅本站的邮件简报,或在 RSS 阅读器中添加本站点以获得及时更新。




你需要手动确认这些文件是否真的可以删除,如果确认的话,手动进行删除。
—
怎么确认?手动在文档里面搜索吗?
emmm 通过脑海中的记忆判断这个图片是否是应该被删除的
博主,测试你的方法,报了编码错误,你那边咋解决的啊。
Traceback (most recent call last):
File "d:\hjroyal\logseq\hj-reading\check_asset_reference.py", line 23, in <module>
for line in f:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xaf in position 672: illegal multibyte sequence
应该是Windows下的编码问题,可以尝试将.py文件以utf8编码保存,并在文件开头加入
# -*- coding: utf-8 -*-,看看能不能修复呢?with open(os.path.join(dirname, filename),encoding=’utf-8′)
谢谢哥哥